=Overview
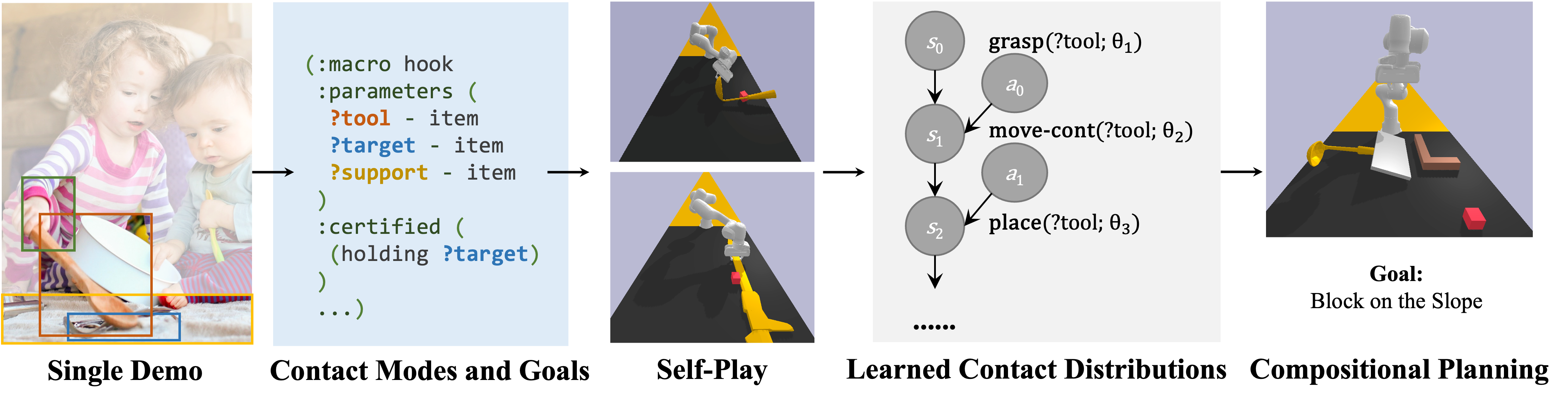
Abstract: Humans demonstrate an impressive ability to acquire and generalize manipulation “tricks.” Even from a single demonstration, such as using soup ladles to reach for distant objects, we can apply this skill to new scenarios involving different object positions, sizes, and categories (e.g., forks and hammers). Additionally, we can flexibly combine various skills to devise long-term plans. In this paper, we present a framework that enables machines to acquire such manipulation skills, referred to as “mechanisms,” through a single demonstration and self-play. Our key insight lies in interpreting each demonstration as a sequence of changes in robot-object and object-object contact modes, which provides a scaffold for learning detailed samplers for continuous parameters. These learned mechanisms and samplers can be seamlessly integrated into standard task and motion planners, enabling their compositional use.
=Key Idea
Mechanisms: some manipulation “strategies” can be modeled by a sequence of contact relationships among objects.
Mechanisms as sequence of contact mode families generalizes to novel objects. We learn these mechanisms, and we compose them.
=Method
There are two learning problems
- Learning of the contact mode sequence. This can be done by parsing the demonstration as a sequence of contact modes using heuristic rules such as gripper states and object-contact events. We do this in simulation.
- Learning samplers for parameters of the contact modes: where to grasp, how to move, etc. We will learn those samplers (parameter generators) from self-plays, in simulation.
=Learned Mechanisms and Experiments

There are four object models used in this mechanism: plate, calculator, caliper, and document.
There are five objects that can be used as the “hook:” wooden L-shape stick, soup ladle, hammer, spoon, and caliper.
There are four “heavy” objects that can be used to flip the plate: box, spoon, dipper, and walnut.
There are three object models that can be used as the “poking” tool: wooden stick, spatula, and spoon.
There are three object models to be placed on the small block: plate, calculator, and document.
There are three object models that can be used as the blocker: wooden stick, wooden L-shape stick, and spoon.
=Compositional Behaviors
(Push-then-Pick-then-Hook) the agent needs to utilize a thin caliper, placed on the table to reach for a distant block. However, the caliper must first be pushed to the table side to enable a successful grasp.
(Hook-then-Place-on-Slope) the agent needs to use a soup ladle as a tool to reach for a distant object. Subsequently, the agent must use either the soup ladle or a brown brick to act as a blocker, preventing the object from falling off a slope.