=Overview
Abstract: Goal-conditioned policies are generally understood to be “feed-forward” circuits, in the form of neural networks that map from the current state and the goal specification to the next action to take. However, under what circumstances such a policy can be learned and how efficient the policy will be are not well understood. In this paper, we present a circuit complexity analysis for relational neural networks (such as graph neural networks and transformers) representing policies for planning problems, by drawing connections with serialized goal regression search (S-GRS). We show that there are three general classes of planning problems, in terms of the growth of circuit width and depth as a function of the number of objects and planning horizon, providing constructive proofs. We also illustrate the utility of this analysis for designing neural networks for policy learning.
=Motivation
Goal: Finding relational neural network policies (e.g., transformers) for planning problems in the same domain.

Figure 1: Exampls of different domains like BlocksWorld, Sokoban, Alfred, and Minecraft
=Circuit Complexity of Planning Problems

Figure 2: Neural networks as "circuits".
Depth: The number of “layers”. Usually, a finite number.
Breadth: The number of “nodes” per layer. Usually, a polynomial of the number of objects in the environment.
Research Question: Finding policies for a family of planning problems in the form of circuits, and the needed circuit complexity.
=Relational Representations of State and Action Spaces
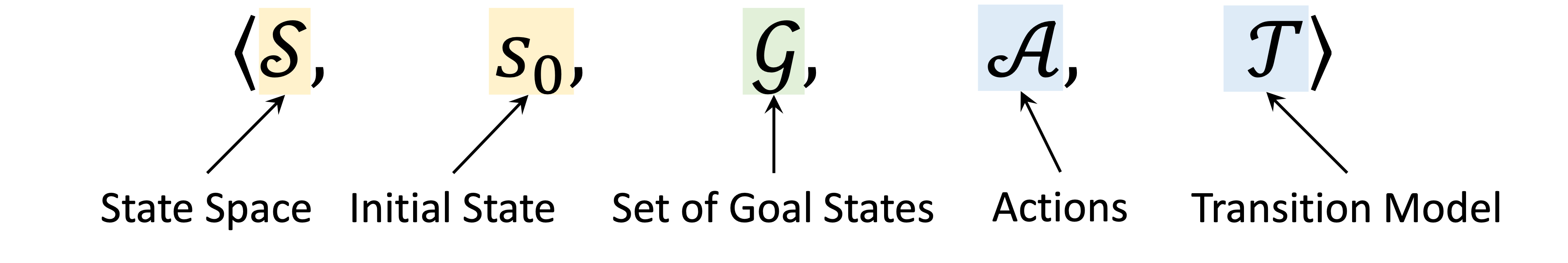 /
/We will focus on problems with object-centric and relational structures. Moreover, for simplicity, we will focus on discrete state and action spaces.
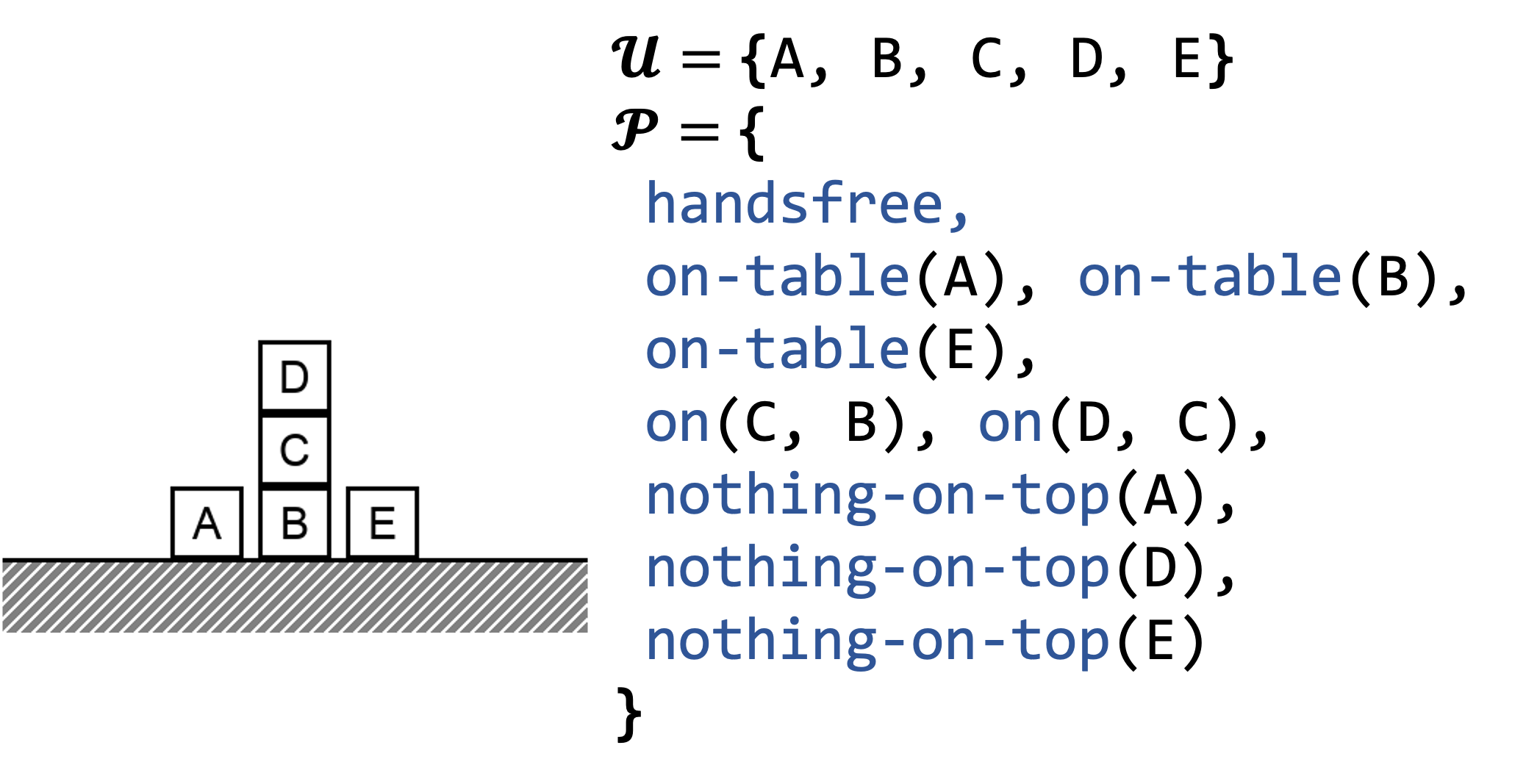
Example: the state contains a set of objects 𝓤, and a set of propositions 𝓟:
- Nullary propositions “handsfree,”
- Unary propositions “on-table,”
- Binary propositions “on.”

Example: the action contains a set of action schemas 𝓐. Each “action schema” has:
- precondition: must be true before execution
- eff+: set propositions to true
- eff-: set propositions to false
=Serialized Goal Regression Search
High-Level Idea: Think about which action can make the goal true. Then, pick an order to sequentially achieve the preconditions of the action.
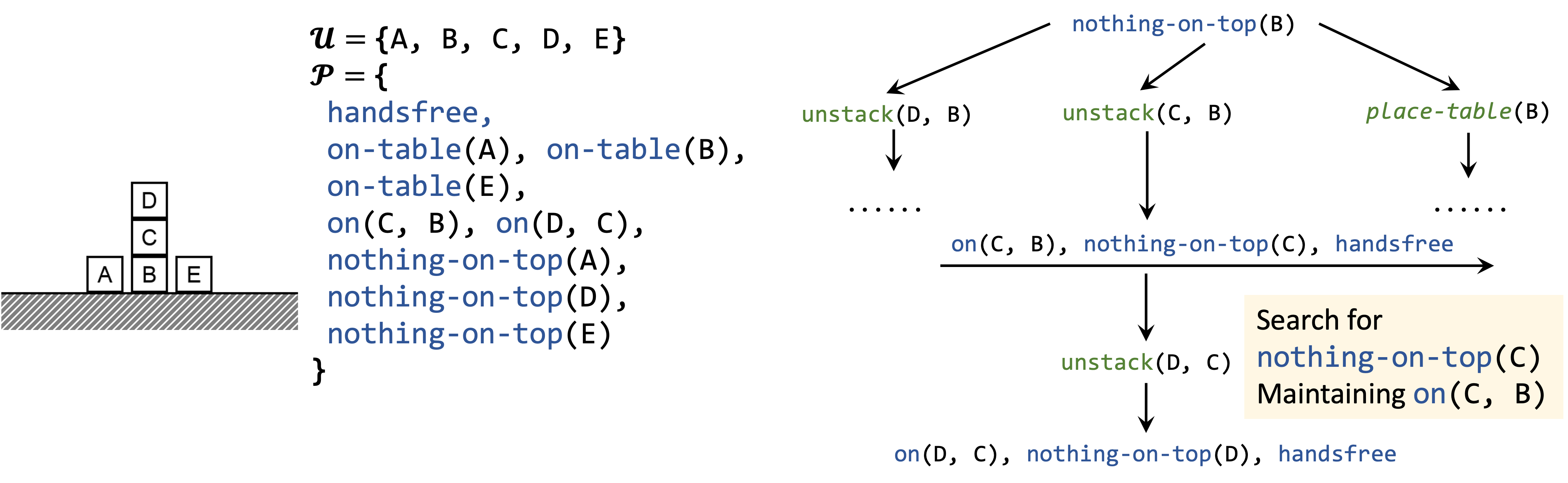
Starting with the highest-level goal nothing-on-top(B), we can first enumerate possible operators that can achieve this goal (e.g., unstack(C, B)). Then, we can pick an order for the preconditions of that action. Note that, for previously achieved goals, we need to "maintain" them while searching for the next goal. In this case, we should not falsify on(C, B) while planning for nothing-on-top(C).
=Theories
Key Ideas:
- An ordering for the precondition may not exist. Therefore, a “good” property of a problem: for states along the solution path, the preconditions can be achieved sequentially.
- Even if we have a set of rules that have precondition ordering along the solution path. The algorithm can still be slow since we need to track an increasing number of “constraints.” Therefore, a “good” property of a set of problems: the maximum number of constraints in the search process is bounded by a constant K.
Result: For a set of problems with the above properties, we can show that the circuit complexity of the policy is polynomial in the number of objects and the planning horizon.
- D = 𝑂(𝑇), 𝑇 is the planning horizon. (see the paper for details about how this can be further reduced!)
- B = 𝑂(𝑁^(𝛽𝐾)), 𝑁 is the number of objects, 𝛽 is the maximum arity of propositions, 𝐾 is the maximum number of constraints.
Proof idea: The serialized goal-regression search runs in polynomial time with respect to the number of objects and the planning horizon. Furthermore, the search algorithm can be compiled into a relational neural network. Relational neural networks actually have the inductive bias of implementing search algorithms!
=Conclusions and Implications
 Figure 6: Many planning problems have a constant constraint size (K).
Figure 6: Many planning problems have a constant constraint size (K).
Some problems can be solved with finite-depth circuits, more of them need an unbounded depth (e.g., 𝑂(𝑁)).
Relational neural networks (e.g., Transformers) actually have the inductive bias of implementing search algorithms.
There are also hard problems where the transition model is simple (as fixed-arity relational transition rule), but the planning problem is hard (e.g., the number of constraints is unbounded w.r.t. the planning horizon or the number of objects). For these problems, learning a relational neural network policy without further assumptions such as sparsity or locality is hard.